Mẹo What is the black-box approach in auditing systems? select all statements that apply.
Thủ Thuật Hướng dẫn What is the black-box approach in auditing systems? select all statements that apply. 2022
Bùi Trung Huấn đang tìm kiếm từ khóa What is the black-box approach in auditing systems? select all statements that apply. được Cập Nhật vào lúc : 2022-11-11 04:34:01 . Với phương châm chia sẻ Bí quyết về trong nội dung bài viết một cách Chi Tiết 2022. Nếu sau khi Read tài liệu vẫn ko hiểu thì hoàn toàn có thể lại Comment ở cuối bài để Ad lý giải và hướng dẫn lại nha.Model-Based GUI Testing
Nội dung chính Show- Model-Based GUI Testing2.1.3 Classification Based on Test Design InformationWhy hackers know more about our systems1.3.6 Limitations of black-box vulnerability detectionEmerging Software Testing Technologies3.3.1 Black-Box TestingSoftware engineeringSoftware validation and verificationManaging the Cost of ChangeGrey box testing: automation over perfectionSecurity Testing5.3.3 Dynamic Taint AnalysisRecent Advances in Automatic Black-Box TestingCombinatorial software testingDomain 6: Security Assessment and Testing (Designing, Performing, and Analyzing Security Testing)Combinatorial Software TestingArchitecture-Centric Testing for Security10.3.2 Penetration testingWhat is the black box approach in auditing systems?Which of the statements below best defines an embedded audit module?What is a continuous audit approach?Is that the attacker steals or makes unauthorized use of a service?
Rupesh Dev, ... Mika Katara, in Advances in Computers, 2012
2.1.3 Classification Based on Test Design Information
Black-box testing: Black-box testing is a testing strategy based on requirements and specifications. Black-box testing requires no knowledge of internal paths, structures, or implementation of the SUT. This testing methodology looks what the available inputs for an application are and the expected outputs that should result from each input. An example of a black-box testing process would be a test automation tool used by a tester. A tester uses the test automation tool with the prewritten test scripts and executes them. But a tester does not necessarily understand any inherent technicalities about the tool and script being used.
White-box testing: White-box testing is a testing strategy based on internal paths, code structures, and implementation of the SUT. White-box testing generally requires detailed programming skills in most cases. A programmer has an understanding of the inherent implementation details and also possesses knowledge of test scripting.
Grey-box testing: Grey-box testing is a software testing technique that uses a combination of black-box testing and white-box testing. Grey-box testing is not complete black-box testing, because the tester does know some of the internal workings of the SUT. In grey-box testing, the tester applies a limited number of test cases to the internal workings of the SUT. In the remaining part of the grey-box testing, a black-box approach can be taken in applying inputs to the SUT and observing the outputs.
The following section elaborates three different types of system testing approaches in which automation work was carried out extensively while preparing the case study. This form of testing is carried out on a daily or weekly basis to hunt for potential bugs in the software itself. Also, hardware-related issues sometimes affect the execution of software testing. Next, these testing methods are described briefly and will be elaborated more in the coming sections.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780123965264000023
Why hackers know more about our systems
Nikolai Mansourov, Djenana Campara, in System Assurance, 2011
1.3.6 Limitations of black-box vulnerability detection
Black-box testing, otherwise known as dynamic testing, is designed for behavioral observation of the system in operation. It has outside-in focus, targeting functional requirements. The activity includes an expert simulating a malicious attack. Testers almost always make use of tools to simplify dynamic testing of the system for any weaknesses, technical flaws, or vulnerabilities. Currently tools in this area are categorized based on their focus of specific areas they are targeting. These areas include network security and software security, where software security is comprised of database security, security subsystems, and Web application security.
•Network security testing tools are focused on identifying vulnerabilities in externally accessible network-connected devices. This activity is performed by either placing packets on the wire to interrogate a host for unknown services or vulnerabilities, or by “sniffing” network traffic to identify a list of active systems, active services, active applications, and even active vulnerabilities. In this case, “sniffing” is considered less intrusive and performs a continuous analysis effort while packet injection techniques produce a picture of the network a given point in time. The strengths and weaknesses related to network security tools could be characterized as follows:
•Packet injection techniques
•Strengths: can be used independent of any network management or system administration information making a much more objective security audit of any system or network and providing accurate information about which services are running, which hosts are active, and if there are any vulnerabilities present.
•Weaknesses: since scanning takes a long time and is intrusive, this type of scanning is performed less often where most solutions opt to reduce the number of ports scanned or the vulnerabilities checked, leading to undiscovered new hosts and a variety of vulnerabilities. In addition, due to restrictive security polices, it is very common for network security groups in large enterprises to be restricted from scanning specific hosts or networks, causing many vulnerabilities to be missed.
•Sniffing techniques
•Strengths: minimal network impact and time needed for scan (scan can be running 24/7).
•Weaknesses: for host or server to be scanned, it needs to communicate on the network, which might lead to discovery of the presence of a server the same time a probing hacker does.
Both techniques giảm giá with very complex log files and they need expertise to interpret them; however, most network administrators do not have sufficient experience and expertise to either properly discern false positives or set priorities for what security holes should be fixed first, which might lead to some critical vulnerabilities not being addressed in time.
In summary, weaknesses of each technique leads to a number of false positives and false negatives, making assessments costly (“weeding” through false positives) and not so assuring (not knowing what has been missed).
Techniques used in black-box software security testing are known as penetration testing. A penetration test uses a malicious attacker behavior to determine which vulnerabilities can be exploited and what level of access can be gained. Unlike network security tools, penetration tools generally focus on penetrating ports 80 (HTTP) and 443 (HTTPS). These ports are traditionally allowed through a firewall to support Web servers. This way they can identify Web applications' and Web services-based applications' vulnerabilities and misbehaviors.
Here are some characteristics of a typical penetration test:
•Strength: A relatively small toolset is needed and serves as a good starting point for more in-depth vulnerability testing. High degree of information accuracy when vulnerability is reported.
•Weaknesses: High number of false negatives and some false positives. Penetration testing works only on a tightly defined scope, such as Web applications and database servers as a less structured process ( least during the system exploration and enumeration phases), which leads to the conclusion that this technique is as good as the tests they run. Penetration technique does not provide the whole security picture, especially for systems that are only accessible via the internal network, and it can be time sensitive. These weaknesses can cause many vulnerabilities to be missed (high number of false negatives) and some server responses could be misinterpreted, causing false positives to be reported.
However, recent developments in the technology areas of System Assurance offer the most promising and practical way to enhance a vendor's ability to develop and deliver software systems that can be evaluated and certified high assurance levels while breaking the current bottleneck, which involves a laborious, unpredictable, lengthy, and costly evaluation process. These breakthrough technologies bring automation to the system assurance process.
This book provides technology guidance to achieve automation in system assurance.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780123814142000014
Emerging Software Testing Technologies
Francesca Lonetti, Eda Marchetti, in Advances in Computers, 2022
3.3.1 Black-Box Testing
Black-box testing, also called functional testing, relies on the input/output behavior of the system. In particular, the system is subjected to external inputs, so that the corresponding outputs are used to verify the conformance of the system to the specified behavior, with no assumptions of what happens in between. Therefore, in this process we assume knowledge of the (formal or informal) specification of the system under test, which can be used to define a behavioral model of the system (a transaction flowgraph) [1]. A complete black-box test would consist of subjecting the program to all possible input streams and verifying the outcome produced, but as stated in Section 2 this is theoretically impossible. For this, different techniques can be applied such as:
•Testing from formal specifications: in this case it is required that specifications be stated in a formal language, with a precise syntax and semantics. The tests are hence derived automatically from the specification, which are also used for deriving inductive proofs for checking the correct outcome [9].
•Equivalence partitioning: the functional tests are derived from the specifications written in structured, semiformal language. The input domain is partitioned into equivalence classes so that elements in the same class behave similarly. In this context, the category partition is a well-known and quite intuitive method, which provides a systematic, formalized approach to partition testing [22].
•Boundary-values analysis: this is a complementary approach to equivalence partitioning, and concentrates on the errors occurring boundaries of the input domain. The test cases are thus chosen near the extremes of the class [22].
•Random methods: they consists of generating random test cases based on a uniform distribution over the input domain. It is a low-cost technique because large sets of test patterns can be generated cheaply without requiring any preliminary analysis of software [23, 24].
•Operational profile: test cases are produced by a random process meant to produce different test cases with the same probabilities with which they would arise in actual use of the software [25].
•Decision tables: the decision tables are rules expressed in a structural way used to express the test experts’ or design experts’ knowledge. Decision tables can be used when the outcome or the logic involved in the program is based on a set of decisions and rules which need to be followed [23].
•Cause–effect graphs: these are combinatorial logic networks that can be used to explore in systematic way the possible combinations of input conditions. By analyzing the specification, the relevant input conditions or causes, and the consequent transformations and output conditions, the effects are identified and modeled into graphs linking the effects to their causes [23].
•Combinatorial testing: in combinatorial testing, test cases are designed to execute combinations of input parameters [23]. Because providing all combinations is usually not feasible in practice, due to their extremely large numbers, combinatorial approaches able to generate smaller test suites for which all combinations of the features are guaranteed, are preferred [24]. Among them, common approach is all-pair testing technique, focusing on all possible discrete combinations of each pair of input parameters. We refer to [26] for a complete overview of the most recent proposals and tools.
•State transition testing: this type of testing is useful for testing state machine and also for navigation of graphical user interface [23]. A wide variety of state transition systems exist, including finite state machines [27], I/O Automata [28], Labeled Transition Systems [29], UML state machines [30], Simulink/Stateflow [31], and PROMELA [32].
•Evidence-based testing: in evidence-based software engineering (EBSE) the best solution for a practical problem should be identified based on evidence [33]. The process for solving practical problems based on a rigorous research approach includes the following different steps that can be applied also to testing activities [34]: (i) identify the evidence and formulate a question; (ii) track down the best evidence to answer the question; (iii) critically reflect on the evidence provided with respect to the problem and context that the evidence should help to solve. In software engineering, two approaches that allow to identify and aggregate evidence are systematic mapping studies and systematic reviews [35].
One of the points against the black-box testing is its dependence on the specification's correctness and the necessity of using a large amount of inputs in order to get good confidence of acceptable behavior.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/S0065245817300529
Software engineering
Paul S. Ganney, ... Edwin Claridge, in Clinical Engineering (Second Edition), 2022
Software validation and verification
The primary purpose of validation and verification (when applied to medical software) is safety. Functionality is a secondary purpose, although without functionality the code is pointless. The way to reconcile this is to enquire as to the failure of the code: a system that is 75% functional but 100% safe is still useable (albeit annoying) – if the figures are reversed, it is not.
In validating and verifying a system as safe, one starts from the premise that all software contains “bugs”. These “bugs” may be classified as faults, errors or failures. A fault is a mistake in the design or code, which may lead to an error (but equally may not), such as declaring an array to be the wrong size. An error is unspecified behaviour in execution, which may lead to a failure, such as messages starting with non-numeric codes being discarded as they evaluate to zero. A failure is the crossing of a safety threshold due to an uncontained error.
There are two main approaches to testing, often referred to as “black box” and “white box”. Applying this to software testing, the “box” is the program, or module, that is to be tested.
In black box testing, the contents of the box are unknown.31 Therefore, tests comprise of a known set of inputs and the predetermined output that this should provide. This is very useful when the software has been commissioned using an Output-Based Specification (OBS) or for end-user testing. It also removes any effect that may be caused by the application of the debugger environment itself.32
In white-box testing (also known as clear box, glass box or transparent box testing, which may be a better descriptor of the process) the contents of the box are known and are exposed. In software terms, this may mean that the source code is available or even that the code is being tested in the development environment via single-stepping. It is therefore usually applied to structures or elements of a software system, rather than to its whole. It is also not unusual for a black box failure to be investigated using white box testing.
In generic terms, therefore, black box testing is functional testing whereas white box testing is structural or unit testing. A large system comprising multiple components will therefore often have each component white box tested and the overall system black box tested in order to test the integration and interfacing of the components.
Testing should normally be undertaken by someone different from the software author. A draft BCS standard (Standard for Software Component Testing) lists the following increasing degrees of independence:
a)the test cases are designed by the person(s) who writes the component under test;
b)the test cases are designed by another person(s);
c)the test cases are designed by a person(s) from a different section;
d)the test cases are designed by a person(s) from a different organisation;
e)the test cases are not chosen by a person.33
There are multiple test case design techniques with corresponding test measurement techniques. ISO 29119 lists the following:
•Equivalence Partitioning
•Boundary Value Analysis
•State Transition Testing
•Cause-Effect Graphing
•Syntax Testing
•Statement Testing
•Branch/Decision Testing
•Data Flow Testing
•Branch Condition Testing
•Branch Condition Combination Testing
•Modified Condition Decision Testing
•LCSAJ (Linear Code Sequence And Jump) Testing
•Random Testing
It is instructive to examine one of these, together with its corresponding measurement technique. The one we will select is Boundary Value Analysis. This takes the specification of the component's behaviour and collates a set of input and output values (both valid and invalid). These input and output values are then partitioned into a number of ordered sets with identifiable boundaries. This is done by grouping together the input and output values which are expected to be treated by the component in the same way: they are thus considered equivalent due to the equivalence of the component's behaviour. The boundaries of each partition are normally the values of the boundaries between partitions, but where partitions are disjoint the minimum and maximum values within the partition are used. The boundaries of both valid and invalid partitions are used.
The rationale behind this method of testing is the premise that the inputs and outputs of a component can be partitioned into classes that will be treated similarly by the component and, secondly, that developers are prone to making errors the boundaries of these classes.
For example, a program to calculate factorials34 would have the partitions (assuming integer input only):
•Partition a: −∞ to 0 (not defined)
•Partition b: 1 to n (where n! is the largest integer the component can handle, so for a standard C integer with a maximum value of 2147483647, n would be 12)
•Partition c: n+1 to +∞ (unable to be handled)
The boundary values are therefore 0, 1, n and n+1. The test cases that are used are three per boundary: the boundary values and ones an incremental distance to either side. Duplicates are then removed, giving a test set in our example of -1, 0, 1, 2, n-1, n, n+1, n+2. Each value produces a test case comprising the input value, the boundary tested and the expected outcome. Additional test cases may be designed to ensure invalid output values cannot be induced. Note that invalid as well as valid input values are used for testing.
It can clearly be seen that this technique is only applicable for black-box testing.
The corresponding measurement technique (Boundary Value Coverage) defines the coverage items as the boundaries of the partitions. Some partitions may not have an identified boundary, as in our example where Partition a has no lower bound and Partition c no upper bound. Coverage is calculated as follows:
BoundaryValueCoverage=numberofdistinctboundaryvaluesexecutedtotalnumberofboundaryvalues×100%
In our example, the coverage is 100% as all identified boundaries are exercised by least one test case (although +∞ and −∞ were listed as the limits of partitions c and a, they are not boundaries as they indicate that the partitions are unbounded). Lower levels of coverage would be achieved if all the boundaries we had identified were not all exercised, or could not be (for example, if 2147483647 was required to be tested, where 2147483648 is too large to be stored). If all the boundaries are not identified, then any coverage measure based on this incomplete set of boundaries would be misleading. The cited paper contains fuller worked examples.
Let us now consider a further level of complexity.
In theory, a software system is deterministic. That is, all of its possible states can be determined and therefore tested, and the resultant system verified. However, although the states and the transitions between them may be finite, the use of multithreaded code and of multicore processors means that the number of test cases becomes unfeasibly large to process. This resultant complexity means that it is more practical to treat the system as being nondeterministic in nature and test/validate accordingly.
Testing therefore becomes a statistical activity in which it is recognised that the same code, with the same input conditions, may not yield the same result every time. In order to demonstrate this, consider the code in Fig. 9.12.

Fig. 9.12. A simple two-threaded program.
On simple inspection, this code would be expected to produce a final value of x of between 10 and 20. However, it can produce values as low as 2 in 90 steps. (As an aside on complexity, this simple piece of code has in excess of 77,000 states) (Hobbs, 2012).
Hobbs defines “dependability” as “A system's […] ability to respond correctly to events in a timely manner, for as long as required. That is, it is a combination of the system's availability (how often the system responds to requests in a timely manner) and its reliability (how often these responses are correct)” (Hobbs, 2012). He goes on to argue that, as dependability is inseparable from safety and dependability results in increased development cost, systems only need to be “sufficiently dependable” where the minimum level is specified and evidenced.
In conclusion, validation and verification may be fully possible. However, it may only be statistically demonstrable.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780081026946000097
Managing the Cost of Change
Bill Holtsnider, ... Joseph Gee, in Agile Development & Business Goals, 2010
Grey box testing: automation over perfection
The opposite of black box testing is called, predictably, white box testing and stresses the product's individual components with full knowledge of the inner workings of the product. Developer tests such as unit tests are a good example of that. Somewhere in between the two is a compromise that gives us our 98% solution mentioned earlier, and because it is between the two, it is sometimes predictably called grey box testing.
Grey box testing takes advantage of some knowledge of the internal workings of the system to make intelligent trade-offs between completeness of testing and manageable test automation.
Grey box testing requires two things to be successful, one that makes some managers and QA engineers uncomfortable and one that makes some developers uncomfortable.
The first is that grey box testing requires careful, constant evaluations to make good decisions on how far to pull open the box to create tests. Opening the box not often enough makes tests difficult to maintain in the face of the rate of development change. Opening the box too much means that defects sneak past the tests more easily and accrue all of the costs we have been discussing. There is no autopilot to testing here.
The second need of grey box testing is designing an application to be testable, which seems like a commonsense statement, but testability is rarely considered an important driver in product design. However, the need to create good interfaces and provide good structural information to tools also pays off here, like it does the unit test level. It creates an architecture that has fewer problems between components because the communication between those components has a clearer structure. It gives us better entry points for future product features, such as enabling new UIs to be layers on existing business logic or opening up application programming interfaces to business partners. This is the same pattern that we have been talking about with regard to test-driven development reapplied a higher level to lead a product to a better architecture.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780123815200000060
Security Testing
Michael Felderer, ... Alexander Pretschner, in Advances in Computers, 2022
5.3.3 Dynamic Taint Analysis
An important variant of black-box testing is an analysis technique called taint analysis. A significant portion of today's security vulnerabilities are string-based code injection vulnerabilities [62], which enable the attacker to inject syntactic content into dynamically executed programming statements, which—in the majority of all cases—leads to full compromise of the vulnerable execution context. Examples for such vulnerabilities include SQL Injection [63] and Cross-Site Scripting [64]. Such injection vulnerabilities can be regarded as information flow problems, in which unsanitized data paths from untrusted sources to security sensitive sinks have to be found. To achieve this, a well established approach is (dynamic) data tainting. Untrusted data is outfitted with taint information on runtime, which is only cleared, if the data passes a dedicated sanitization function. If data which still carries taint information reaches a security sensitive sink (eg, an API that converts string data into executable code), the application can react appropriately, for instance through altering, autosanitization the data or completely stopping the corresponding process. If taint tracking is utilized in security testing, the main purpose is to notify the tester that insecure data flows, that likely lead to code injection, exist. Unlike static analysis, that also targets the identification of problematic data flows, dynamic taint analysis is conducted transparently while the application under test is executed. For this, the execution environment, eg, the language runtime, has to be made taint aware, so that the attached taint information of the untrusted data is maintained through the course of program execution, so that it can reliably be detected when tainted data ends up in security sensitive sinks.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/S0065245815000649
Recent Advances in Automatic Black-Box Testing
Leonardo Mariani, ... Daniele Zuddas, in Advances in Computers, 2015
2 Overview
Recent advances in automatic black-box testing have produced relevant results in four main areas: random testing (RT), MBT, testing with complex inputs, and combinatorial interaction testing (CIT). Figure 1 illustrates the main advances that we discuss in this chapter, and presents the taxonomy that we use.
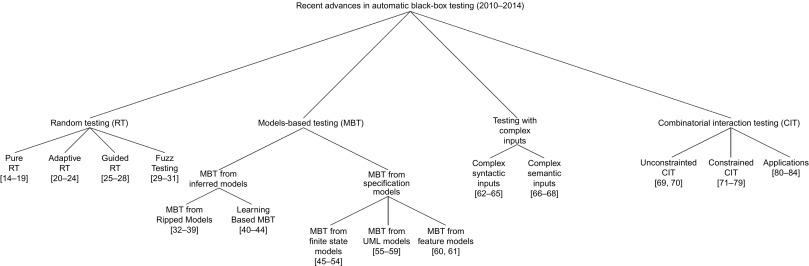
Figure 1. Recent advances in automatic black-box testing.
Random testing is a research area that is gaining increasing attention, after being nearly completely ignored for almost two decades. Random testing has attracted a lot of research interest from 1980s to 1990s, but without producing conclusive results [85, 86]. In the recent years, empirical and theoretical studies have contributed to clarify the role and the (nontrivial) effectiveness of random testing [14–16, 18]. More importantly, the research community has recently defined several approaches that extend random test case generation with informed and heuristic decisions that dramatically improved the capability to explore and sample the execution space [20, 21, 27, 30, 87, 88]. These algorithms, often referred to as randomized test case generation algorithms, since they include a significant number of random decisions but are not purely random, demonstrated their effectiveness and will likely influence research in black-box test case generation for the next few years.
MBT is a well-established and active research area, as suggested by the many papers published since the early seventies and from 2010 to 2014. We identified two main trends in MBT research and development: MBT from inferred modes, which is based on the novel idea of automatically deriving the models that can support test case generation from the application under test [32, 35, 40, 44]; and MBT from specification models, which consists in further developing and improving the well-established approaches about deriving test cases from specification models [45–47, 52, 55, 57, 61].
Techniques for deriving models from software artifacts have been studied and applied for a long time, but models dynamically derived from program executions have been only recently generated with the specific purpose of being used as software specifications. Modern approaches to generate specification models are often referred to as specification mining techniques. Examples of well-known specification mining techniques are Daikon [89], GK-tail [90], and Adabu [91]. Models obtained with specification mining techniques have been exploited for test case generation in multiple contexts, such as unit testing [92], integration testing [93], and system testing [94]. Recent approaches in black-box MBT have exploited models inferred from software mostly in the context of system testing [32, 33, 44]. The definition of testing approaches working with inferred models is a promising research direction that can perspectively overcome issues related to the costs of defining models that typically affect MBT.
Recent advances in testing based on specification models giảm giá with three classes of popular models: finite state models [45, 48], UML models [56, 57], and feature models [60, 61]. Differently from testing based on inferred models, research in testing based on specification models has mostly focused on consolidating technical and scientific results, and on investigating specific aspects related to test case generation, for instance on generating optimal test suites from finite state models [52, 95].
Testing with complex inputs is a novel research area which aims is to generate inputs for functionalities that require complex data to be executed. Inputs might be complex for both syntactic reasons, for instance a method that requires a complex graph of objects as parameter, and semantic reasons, for instance a form that requires an address in a real city of a real country. The generation of syntactically complex inputs has been investigated only recently. After the early work on KORAT that addressed the construction of nontrivial data structures [96], recently many researchers have proposed new interesting approaches, due to the increasing popularity of applications that process real-world data, for instance gps systems and map services. This is a novel and promising research direction that will likely gain increasing attention, to a large extent due to the continuously increasing diffusion of software services that interact with physical and social systems.
Combinatorial interaction testing (CIT) has been introduced in the early nineties as a way to find a compromise between effort and effectiveness when testing interactions between multiple parameters [97–99]. Despite the long history of CIT, the research community is still actively working on the problem of generating test cases covering interactions between parameters. While little activity has been recorded for unconstrained CIT, a number of approaches have been recently defined to address the case of constrained CIT, in particular CIT problems proposed with a set of logical constraints to be satisfied [71, 74].
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/S0065245815000315
Domain 4
Eric Conrad, ... Joshua Feldman, in CISSP Study Guide (Second Edition), 2012
Combinatorial software testing
Combinatorial software testing is a black-box testing method that seeks to identify and test all unique combinations of software inputs. An example of combinatorial software testing is pairwise testing (also called all pairs testing).
NIST gives the following example of pairwise testing: “Suppose we want to demonstrate that a new software application works correctly on PCs that use the Windows or Linux operating systems, Intel or AMD processors, and the IPv4 or IPv6 protocols. This is a total of 2 × 2 × 2 = 8 possibilities but, as [Table 5.1] shows, only four tests are required to test every component interacting with every other component least once. In this most basic combinatorial method, known as pairwise testing, least one of the four tests covers all possible pairs (t = 2) of values among the three parameters.” [32]
Table 5.1. NIST Pairwise Testing Example [33]
Test CaseOSCPUProtocol1 Windows Intel IPv4 2 Windows AMD Ipv6 3 Linux Intel Ipv6 4 Linux AMD Ipv4
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9781597499613000054
Domain 6: Security Assessment and Testing (Designing, Performing, and Analyzing Security Testing)
Eric Conrad, ... Joshua Feldman, in CISSP Study Guide (Third Edition), 2022
Combinatorial Software Testing
Combinatorial software testing is a black-box testing method that seeks to identify and test all unique combinations of software inputs. An example of combinatorial software testing is pairwise testing (also called all pairs testing).
NIST gives the following example of pairwise testing (see: ://csrc.nist.gov/groups/SNS/acts/documents/kuhn-kacker-lei-hunter09.pdf), “Suppose we want to demonstrate that a new software application works correctly on PCs that use the Windows or Linux operating systems, Intel or AMD processors, and the IPv4 or IPv6 protocols. This is a total of 2 × 2 × 2 = 8 possibilities but, as (Table 7.1) shows, only four tests are required to test every component interacting with every other component least once. In this most basic combinatorial method, known as pairwise testing, least one of the four tests covers all possible pairs (t = 2) of values among the three parameters.” [6]
Table 7.1. NIST Pairwise Testing Example [7]
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780128024379000072
Architecture-Centric Testing for Security
Sarah Al-Azzani, ... Rami Bahsoon, in Agile Software Architecture, 2014
10.3.2 Penetration testing
Penetration testing takes the form of black-box testing of the system using a predefined set of test cases that represent known exploits. It is performed using either existing tools [20,21] or by hiring security experts that try to attack the system and exploit any potential weaknesses in the system. Although this approach is attractive, its main problem with respect to agile development is that it is not design-specific testing; testers run the same set of test cases on different systems and rely on the fact that developers often make similar mistakes and repeat them. In addition, penetration testing—whether done by hiring a red-team or by using vulnerability-scanning tools—addresses known attacks, but determined attackers often look for novel ways of attacking a system. The system’s response to such attacks is observed and any inappropriate behavior is noted. This process requires knowledge of both the desired behavior and certain implementation details that are the source of vulnerabilities [22]. Although redesigning a feature in agile development might not be expensive to perform, patching a system is cheaper and is likely to be considered before redesign. This step attempts to hide the symptoms of the problem as opposed to fixing it, which may bring many issues into the system such as writing a vulnerable patch or discovering new symptoms of the problem.
Security tools used in penetration testing, such ISS Scanner [23] and Cybercop [24], are generally limited in scope. They mainly address network security attacks, and are not flexible enough to allow testers to write custom attacks. Another problem with existing tools is that they can only be used after the system is built. In addition, most tools address IP networks; thus, a company wishing to test a different type of networks is required to purchase different tools as required. Although these “badness-ometers” [25] are useful in displaying the negative state of the system, especially when the system configuration is well understood, they are not useful in nonstandard applications, and hence should not be the only way of testing an application. Other forms of security tools are static analysis tools that address code vulnerabilities, such as buffer-overflow. Both are very limited in scope since dynamic testing is also important, and both have high false-positive error rates.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780124077720000095
What is the black box approach in auditing systems?
Black box approach is where the auditor is basically not well versed about the computer processing, it is also know as audit around the computer, where documents are taken in physical form and audit techniques are applied on them.Which of the statements below best defines an embedded audit module?
Which of the statements below best defines an embedded audit module? A module in which the auditors create fictitious situations and perform a wide variety of tests over the system.What is a continuous audit approach?
A continuous audit is an internal process that examines accounting practices, risk controls, compliance, information-technology systems, and business procedures on an ongoing basis. Continuous audits are usually technology-driven and designed to automate error checking and data verification in real time.Is that the attacker steals or makes unauthorized use of a service?
Misappropriation is an attack in which the attacker steals or makes unauthorized use of a service. Tải thêm tài liệu liên quan đến nội dung bài viết What is the black-box approach in auditing systems? select all statements that apply.
Post a Comment